I Hate Test Memes Funny I Hate Practice Memes
Hateful Meme Detection
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes.

We all would have come across many meme images in our social media feeds. The meme images can be informative, funny, hateful or even meaningless. But, meme images is very lucrative and innovative ways to spread and seed ideas into an normal social media user. Creating Meme's and sharing it may have been started as fun leisure. But, now these Meme's can make a huge social and political, it can be used as a media tool by both the extremists and liberals. The social media platforms are spending and creating modules and personal teams to filter the images and memes which is uploaded by the user. This is where the Deep Learning techniques come in for the rescue. The modules build up to filter images in social media is faster and cheaper.
The Meme images are difficult to filter by the available modules for filter the social media images due to the multimodal nature of the Meme Images. Since, memes are have two different features in it usually. One is the Image features and other is the text features. And, Memes needs a multimodal reasoning to classify it hateful or Not-hateful. To create deep Learning models to classify the memes into hateful or not-hateful, the Hateful Memes Challenge is a multimodal classification problem put up by Driven Data with the Dataset Provided by Facebook AI with this paper.
Introduction
The Authors of the paper collected thousands of hateful memes which are multimodal in nature. Memes are all over the internet. Take an image and add some text, if it conveys a meaning then it's a meme. Memes are often harmless and sometimes informative and funny. Like, In all the art forms of the modern age, the hatefulness or meanness towards an individual or groups can be expressed through these memes. And, with the advent of the Digitalization of nook and corner of the world. This gives an opportunity to put these hateful memes on a public platform like social media which can and will be harmful to the people which it is targeted towards. The Models which are available for hateful meme detections are unimodal in nature. The Prediction is either predominantly based on the text signals or image signals but not on both. It is particularly hard for the available models to classify multi-modal problems. This Challenge dataset proposed by Facebook AI is constructed with a scientific process with the team of annotators in a way to address the detection of hateful memes with the benign confounders in the Dataset to force the models not to bias towards only text or image signals but on both.
Business Problem
According to Mike Schroepfer, Facebook CTO, they took an action on 9.6 million pieces of content for violating their HS policies in the first quarter of 2020. This amount of malicious content cannot be tackled by having humans inspect every sample. Consequently, machine learning and in particular deep learning techniques are required to alleviate the extensiveness of online hate speech. To, tackle this problem, Facebook AI's releases the Challenge Set which encourages Researchers and scholars to build a model which classifies the memes into hateful or not hateful. :Detecting hate speech in memes is challenging due to the multimodal nature of memes (usually image and text) and pose an interesting multimodal fusion problem.
Consider a sentence like "love the way you smell today" or "look how many people love you". Unimodally(separately), these sentences are harmless, but combine them with an equally harmless image of a skunk or a tumbleweed, and suddenly they become mean and harmful. That is to say, memes are often subtle and while their true underlying meaning may be easy for humans to detect, they can be very challenging for AI systems.
Most of the available AI systems are not good at subtle reasoning like the humans. The Human accuracy in correctly predicting the memes as hateful or not is 84.7%, whereas, the state of the art methods performs poorly with 64.7% accuracy. The Main reason for the poor performance is the models are not good with subtle reasoning as humans do. These models are most unimodally biased in predicting the classes. Either the memes are classified based on their text or image signals not on both signals. Most of the available AI systems are not good at subtle reasoning like the humans. The Human accuracy in correctly predicting the memes as hateful or not is 84.7%, whereas, the state of the art methods performs poorly with 64.7% accuracy. The Main reason for the poor performance is the models are not good with subtle reasoning as humans do. These models are most unimodally biased in predicting the classes. Either the memes are classified based on their text or image signals not on both signals.
DL Formulation
The Problem at our hand, is to build a model which can detect whether a meme is hateful or not? And, the model should predict based on both the image and text features and not biased towards one over other. In other Words, Multimodal in Nature. So, For this task the Challenge set is provided by Driven Data. More Exploration on the Dataset provided can be seen later in Data Overview. To build a model from the Image Dataset which contains Multimodal memes, we need to extract features from the pixels and text of these memes and use these features to predict the binary Classification problem of Hateful Meme Detection.
Data Overview
Facebook AI provides 10000 images, classified into a train set (8500 pictures), development set (500 images) and a test set of 1000 images. In the Competition Page, a downloadable Zip File provided.
The zip file consists of the following files:
- LICENSE.txt — the data set license
- README.md — the data set readme
- img/ — the directory of PNG images
- train.jsonl — the training set- is an unbalanced dataset with a hateful rate (35/65)
- dev_seen.jsonl — the development set for the Phase 1 leaderboard, it is a balanced Dataset with a hateful rate of 50/50.
- dev_unseen.jsonl — the development set for the Phase 2 leaderboard
- test_seen.jsonl — the test set for the Phase 1 leaderboard
- test_unseen.jsonl — the test set for the Phase 2 leaderboard
And a submission format CSV file is provided for the submission to competition.
img/ img folder contains all the images of the challenge dataset including train, dev and test. The total number of images in the image folder is 12,140 images. train.jsonl, dev_seen.jsonl, test_seen.jsonl — It is a json file where each line has a dictionary of key-value pairs of data about the images. The dictionary includes
"id" — This is a unique identifier of the Meme Image.
"Img" — The folder path of the Meme Image.
"label" — Label of the Meme Image 0: not-hateful 1: not-hateful
"text" — The Text in the Meme.
One Example:
{"id":42953,"img":"img/42953.png","label":0,"text":"its their character not their color that matters"}
The test_seen.jsnol have all the above mentioned key-value pairs except the Label.
Performance Metric
Since, the case-study is a competition, the performance or evaluation metric provided by Facebook AI is area under the receiver operating characteristic curve (AUROC or AUC). The AUROC ranges from 0 to 1. The goal of the competition is to maximize the AUROC.
Another metric given to measure performance is accuracy. Accuracy calculates the percentage of rows where the predicted class in the submission matches the actual class in the test set. The maximum is 1 and the minimum is 0. The goal is to maximize the classification accuracy also.
Existing Approaches
- VilBert-Visual and Language Bert is an existing model for learning task-agnostic joint representations of image content and natural language. This model extends the popular BERT architecture to a multi-modal two-stream model, processing both visual and textual inputs in separate streams that interact through co-attentional transformer layers. This model through two proxy tasks on the large, automatically collected Conceptual Captions dataset and then transfer it to multiple established vision-and-language tasks — visual question answering, visual commonsense reasoning, referring expressions, and caption-based image retrieval — by making only minor additions to the base architecture. This model achieves an 70.31 AUROC score on the test data of Hateful Memes Challenge.
- Visual BERT-consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention. This model pretrained on VQA, VCR, NLVR2. This model achieves an 71.41 AUROC score on the test data of Hateful Memes Challenge.
Exploratory Data Analysis
Since the Dataset contains lots of hateful memes, I personally want to put more hateful images on my blog because it may hurt people. In don't want to be an vector for this hateful memes.
The meme images have both the text and images. And, the team which is developed by the hateful meme challenge dataset introduced confounders in the dataset. The text and image confounders are the memes which shares image or text respectively but with different labels. In the Image above, both the images have same text "Love the Way you Smell today". If the text was on the skunk picture, it is hateful. if the same text is on the image of the rose, the the meme is not-hateful. The same can be done with the text swap on the image to change the label.
First Cut Approach
The first cut approach is the extract the features from the images using pre-trained models like ResNet-152. And, the text are embedded using the Pre-trained BERT. The features are simply concatenated and passed through a Feed forward network classifier to train the data. This approach doesn't increase the AUROC score at all. The training doesn't improve the AUROC score and decrease at all.
Another approach is to train the resNet-152 and BERT encoders also in the concatenate model while training the data. This change in concatenate model is also doesn't improve model performance in the train and validation data. The reason for the performance of the concatenate model is the features concatenation leads distortion of the features vectors and makes it impossible to the classifier Deep Neural Network to learn. In Plain words, Garbage In and Garbage Out.
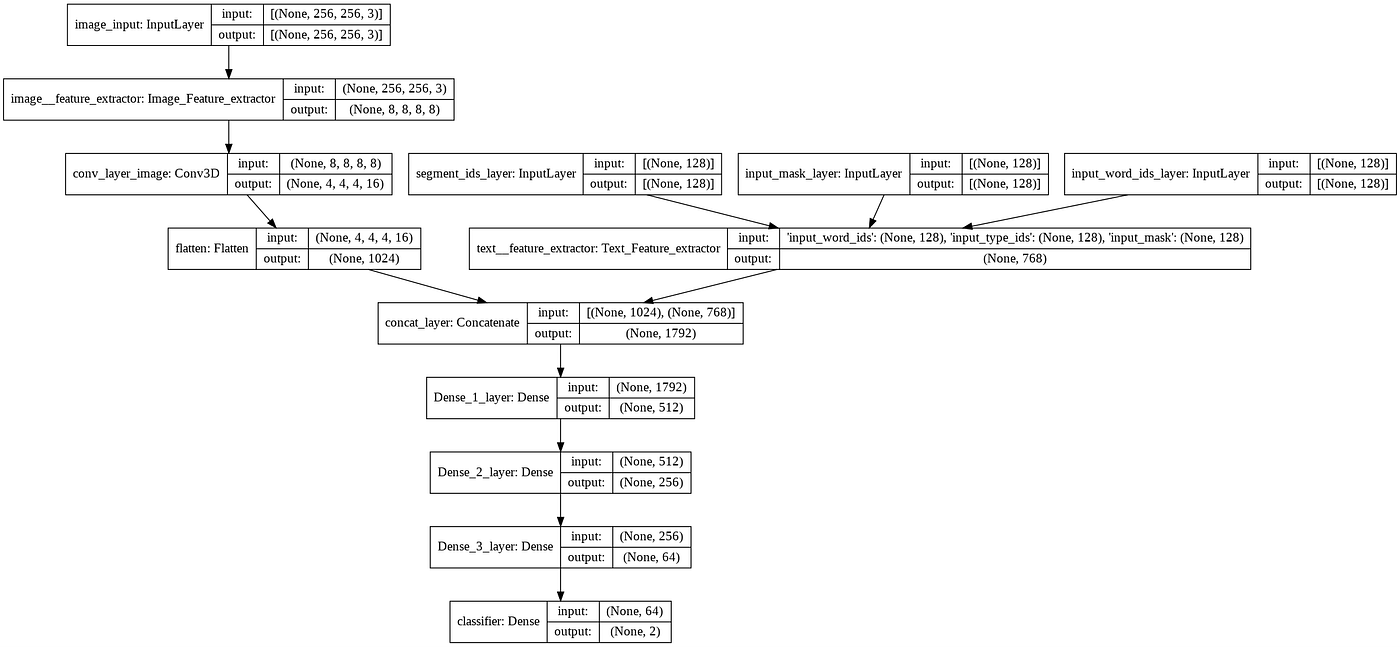
Self-Attention Model
The Self-Attention model is another approach for the classification of Hateful memes. The Self-Attention model is based on the Image caption model. The Model Basic Architecture have Encoder and RNN Decoder model. The encoder model is a Model which extract the features from the images and text using the ResNet-152 and BERT respectively.
The CNN Encoder extract the features from the image and text separately. The Bahdanau Attention module is used to assign the attention weights to the image features. The Decoder input is the text features concatenated with context vector from the Bahdanau Attention layer. The RNN layer's output is passed into a Deep Neural networks classifier. The model learns from the attention and RNN layer.
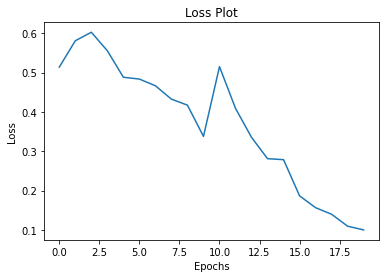
The Self-Attention model is compiled with the loss Categorical Cross Entropy and trained with simple Adam Optimizer. The model is trained for 20 epochs on the balanced train data. At the end of 30 epochs, it achieved the AUROC score of the 0.998.
The self-attention model achieves 0.724 AUROC score on the validation Data.
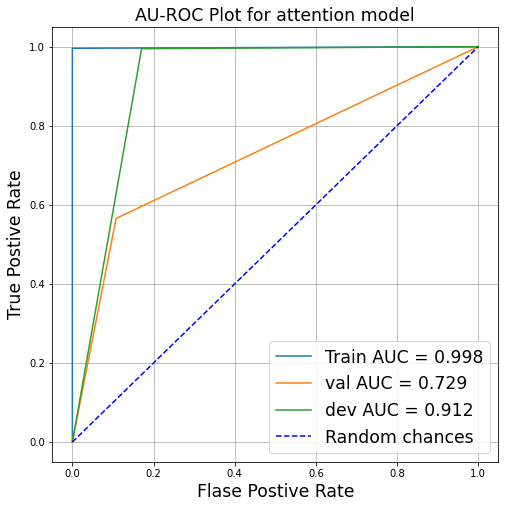
Investigation on the Model
The Little Investigation on the Self-attention Model can reveal the reasons for its performance. The confusion matrix plotted to analyze the False Positives and False Negatives.
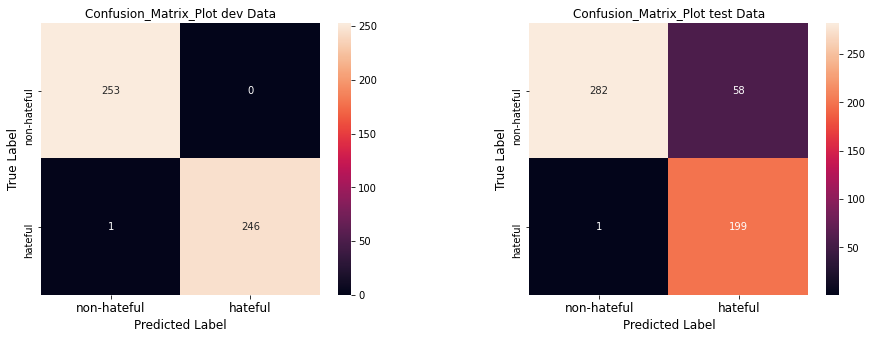
The number of False Positives is less in both the training and test data. That is an indication of good performance. The business problem is to filter hateful memes, even if the non-hateful memes are identifies as the hateful(False Negatives), it might not be a problem, it doesn't affect the user's experience.
Deployment Of Final Model
The Self Attention Model is a Large model which conglomerates three Models (ResNet-152, Bert and Self-Attention) within itself. To deploy the model in the Cloud Platform Heroku or local VM's, we need to Quantize the model to reduce it's size to deploy. Here, tensorflow-lite is used to quantize the model. By saving the weights and loading the weights using the tensorflow-lite. The app for Hateful Meme Detection is done on the Local VM. The Demo video of the deployed model is given below.
Conclusion
The Self-attention model is better at predicting the hateful memes. This is final model I developed for the Hateful Memes Classification. The model achieves the validation score of 0.729 AUROC score on the Validation Data. The whole project with the full code in the Github repo.
Future Work
- Using More attention heads to learn the relationship between the text and Image to increase the model's performance.
- The co-attention can be replaced in place of self attention to attain the weights learned from both the images and text.
- train the networks with the proxy tasks like VQA can help in increase the performance.
- And, Finding ways to better fit to the image and text confounders.
References
- The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes
- Detecting Hate Speech in Memes Using Multimodal Deep Learning Approaches: Prize-winning solution to Hateful Memes Challenge
- Detecting Hateful Memes Using a Multimodal Deep Ensemble
- Multimodal Learning for Hateful Memes Detection
- A Multimodal Framework for the Detection of Hateful Memes
- VilBERT
- https://www.appliedaicourse.com/
GitHub Repo:
LinkedIn Profile: Praveen Jalaja
blackwoodfelf1976.blogspot.com
Source: https://medium.com/codex/hateful-meme-detection-3c5a47097a08
0 Response to "I Hate Test Memes Funny I Hate Practice Memes"
Post a Comment